Creating or Updating Profiles in Bulk
Populating tables in bulk is possible through the ACTITO APIs, which allow mass imports based on zip files containing profile data. The format expected to be able to process these files will be detailed thereafter.
The APIs also allow you to directly monitor your imports by retrieving its status and potential error causes.
Importing profiles in bulk
There is an operation which allows mass profile imports through the ACTITO public APIs: POST/entity/{e}/table{t}/import
This call enables you to post a ZIP file that contains a CSV with the profile data to be uploaded.
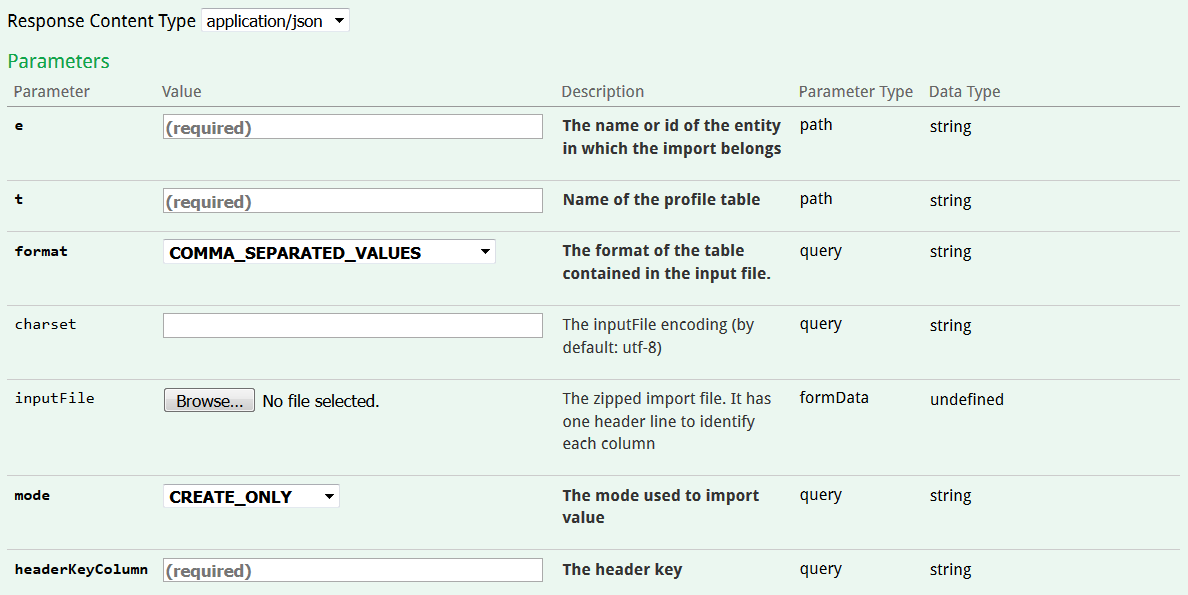
The following parameters must be supplied:
the name of entity to which the profile table belongs
the name of the profile table in which you want to import data
the formatof the CSV file. 3 formats of CSV files are allowed:
COMMA_SEPARATED_VALUES (',' and line-break separator)
TAB_SEPARATED_VALUES (tab and line-break separator)
SEMI_COLON_SEPARATED_VALUES (';' and line-break separator)
"charset": Encoding of the CSV file. Default value is UTF-8.
the import mode. There are 3 possible values:
CREATE_ONLY: Load data only if they do not match any existing record in the table. In other words, the line value for the selected "headerKeyColumn" cannot exist in the database.
UPDATE_ONLY: Load data only if they match an existing profile in the table. It consists exclusively in updating existing profiles.
CREATE_UPDATE: Create a new profile if no matching profile is found in the database and update already existing profiles.
"headerKeyColumn": Name of the column of the CSV file that will used as unique data identification key. It must correspond to a unique field from the table in which data will be loaded.
File format
The file on which the import will be based must be ZIP file containing a single UTF-8 CSV file.
To get to know the file format specific to your profile, you can use the GET operations used to obtain the structure of your table.
Columns format
The first line of your file will serve as header of the column. It defined the number of columns in the file.
Please note that:
Every line of the file must match the number of columns defined in the header.
Two columns cannot bear the same name.
Every header name must be the technical name of a field of the table (attributes, subscriptions or segmentations). Case sensitivity is taken into account:
A column is needed for each subscription. As subscriptions are not really profile attributes, their column names must fit a specific format:
'subscriptions#xxxx' where 'xxxx' is the same of the subscription.A column is needed for each segmentation. As segmentations are not really profile attributes, their column names must fit a specific format:
'S_xxxx' where 'xxxx' is the name of the segmentation.
Multi-value attributes are currently not accepted.
Values format
The format that each value must take can be obtained by doing a GET request in order to retrieve the structure of the profile table. For a file to be valid, it is necessary to fit the expected formats, such as they are defined below:
Subscriptions
The expected value for subscription is a Boolean with "true" and "false" as possible values.
Simple segmentations
In the case of a simple segmentation, indicate "Member" if the profile belongs to the segmentation and leave the field empty if not.
Exclusives segmentations
In the case of an exclusive segmentation, the expected value is the name of the segment sub-category in which the profile must be inserted. If the segmentation is not mandatory, leave the field empty to state that the profile should not be put in any category of the segmentation.
Date
String of characters matching one of the following formats:
YYYYMMDD
YYYY-MM-DD
dd/MM/yyyy
Moment
String of characters matching one of the following formats:
YYYYMMDD
YYYY-MM-DD
dd/MM/yyyy
YYYYMMDDhhmmss
YYYY-MM-DD hh:mm:ss
dd/MM/yyyy HH:mm:ss
MM/dd/yyyy hh:mm:ss AM|PM
Country
String of characters representing the ISO 3166-1 two letters code of the country, or its name in lower case.
For example:
belgium or BE
austria or AT
algeria or DZ
…
Langues
String of characters representing the ISO 639-1 two letters code of the language, or its name in lower case.
For example:
dutch or NL
german or DE
french or FR
…
Gender
Possible values: M or F
Tip
Download an example of a zipped CSV import file: ProfileImportExample.zip
Response to the call
Successful call
The response to a successful import call is the technical id of this import.
Please not that just because the call is successful does not mean that the import is successful. The obtained id will let you check that all profiles have been correctly imported.
Error during the call
Some errors are directly indicated in the response to the call via a 400 error code.
The response body will contain a specific error code that will complete this general error. There are indeed several possible explanations :
"HEADER_NOT_FOUND_IN_ACTITO": The names of the headers of your CSV file do not exactly match the technical name of the attributes found in your database. They are case sensitive.
"NOT_FOUND" : The field supplied as "headerKeyColumn", which is the unique identification key, cannot be found among among the headers of your file.
"INVALID_FIELD_VALUE" : You did not specify any "headerKeyColumn" in your call. Indicating a unique attribute as "headerKeyColumn" is mandatory, unless your table has an auto-generated business key.
Obtaining the import status and result
If the call is successful, several operations stand at your disposal to check the progress of your import. They are grouped in the 'import-controller' category.

The operation GET/entity/{e}/import/{i}/status will let you obtain the status of the import, which means whether the import is still running or finished.
To do so, indicate the entity on which the import was created, as well as the technical id of the import obtained as response to the call.
There are 3 possibles status:
RUNNING: The import is still in progress. You need to wait for its completion.
FINISHED: The import is complete and the result is ready (see below).
IN ERROR: The import has failed and was not completed properly. In such a case, it means that the whole job has failed, not that a part of the data could not be imported. Only the result of the import will tell you if specific data entries could not be imported.
The operation GET/entity{e)/import{i}/result will allow you to obtain the result of the import, which means whether the import could be completed as a whole or if there are errors.
Supplied parameters are also the entity on which the import was created as well as the technical id of the import obtained as response to the call.
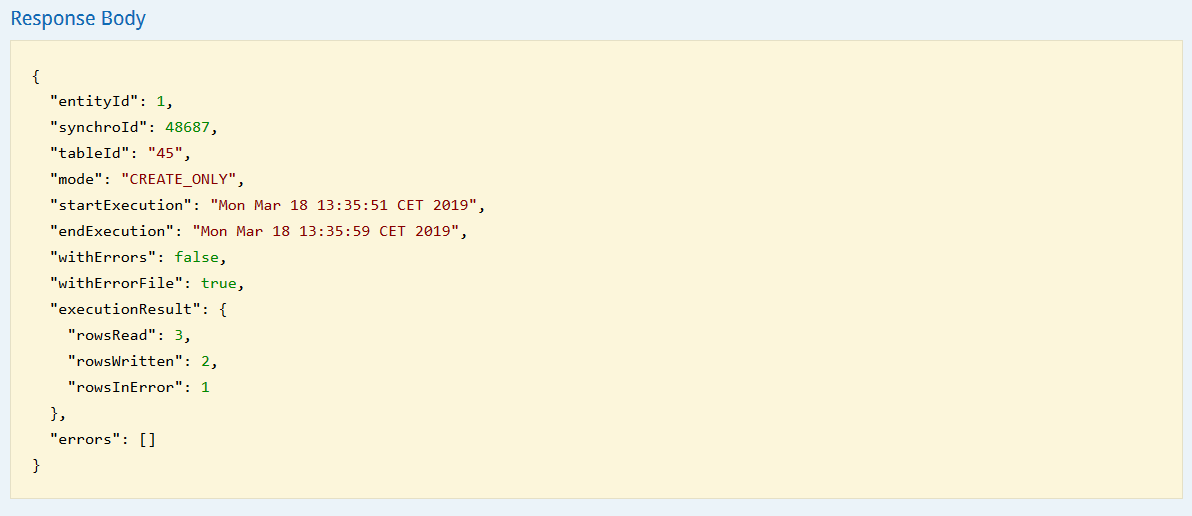
The obtained result will give you on the one hand:
The technical id of the entity, of the import and of the profile table.
The creation mode
The start and end moments of the import execution
On the other end, potential errors will be signaled with the following parameters:
"withErrors": Boolean stating if the import execution encountered a global error. The import could not be completed and no data has been processed at all.
"withErrorFile": Boolean showing whether there is an error file available to download. If the "withErrorFile" is set as "true", the file has been processed but some lines could not be imported because of a format or an integrity error. Even if all lines failed, it does not mean there was a global error.
"executionResult": Result of the execution. There will be data available there only if there is no global error.
"rowsRead": Number of rows taken into account at this stage.
"rowsWritten": Number of rows recorded at this stage and for which the import is therefore successful.
"rowsInError": Number of rows not processed because they failed.
"errors": This information will be only available if there is a global error that prevented the processing of the file. It will give the row or column where the error occured.
Tip
The number of "rowsWritten" is the number of effectively updated or created entries. Already existing entries are not taken into account. Therefore, the number of "rowsWritten" can be lower than the number of "rowsRead" even if there is no error.
Result with global error
A global error implies an error linked to the format of the file rather than a line in particular. However, this kind of error is not severe enough to lead to a failure of the call directly when attempting to create the import.
A global error is signaled by a "withErrors" parameter set as 'true' in the result. An error code will be thereafter indicated in the "errors" parameters.
It may be one of the following codes:
"INVALID_LINES": A row is invalid, for example because it has an extra column
"DUPLICATE_HEADERS": There is a duplicate in the header names of the file
Retrieving the error file
If the import did not fall into a global error but that specific rows are not correct, the "withErrorFile" will be set as "true".
You will therefore be able to retrieve the detail of each error through a file. To do so, there is the operation GET/entity/{e}/import/{i}/errors
Supplied parameters are the entity on which the import was created as well as the technical id of the import obtained as response to the call.
Tip
In the Swagger technical documentation open the URL address under the 'Request URL' section to retrieve the error file more easily
You will obtain the ZIP file named "resultImportId", where "importId" is the technical id of the call such as you obtained it at its creation.
This ZIP file contains a CSV error file with a replica of each failed row, but with 2 extra columns:
"errorCode": This is the error code, which details the reason for failure.
"errorColumn": This indicates in which column is the error.
If several columns fell into error for the same row, this row will be repeated once for each error.
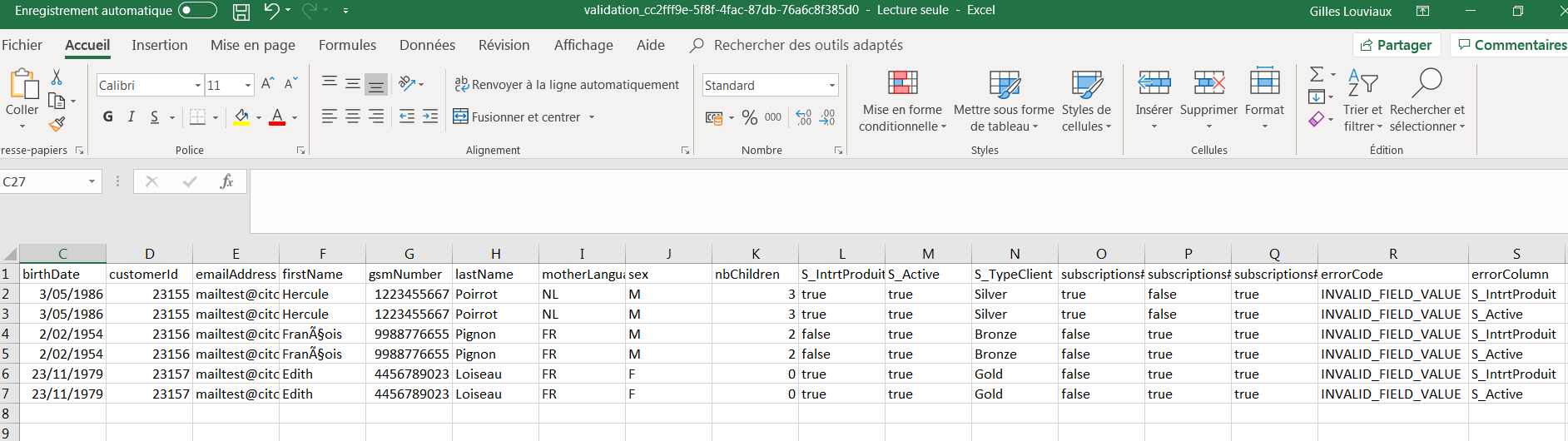
In this example, 3 profiles failed because of an invalid value format for two segmentations columns. Indeed, as explained in the 'Values format' point, in the case of simple segmentations, the expected format is either "Member" or an empty cell, not a true/false Boolean.
Typical error cases
The most frequently encountered error codes are as follows:
"INVALID_FIELD_VALUE": The row value for the field indicated in the 'errorColumn' row is not valid, because the format is not compatible.
"DATA_ALREADY_EXISTS": The error occurs because the data already exists in the table. It also occurs in 'createOnly' mode when a row of the import file refers to a business key that already exists in the table.
"UNKNOWN_DATA": The error occurs because the data already exists in the table. It also occurs in 'updateOnly' mode when a row of the import file refers to a business key that does not exist in the table.
"DUPLICATE_OBJECT": The error occurs because the new record contains an existing value for a unique attribute which is not the business key.
"MISSING_FIELD_VALUE": The error occurs because the value for a mandatory attribute is missing.